Parser Guidelines
Introduction
Parser guidelines aim to provide the typical practices expected to be followed to successfully build and execute a Python-based parser.
Pre-requisites
To get started with parser creation, you are required to have knowledge of Python (latest version).
You should also have access to LDAS v2025.1.0 and the Instrument Integration component of LDAS.
Parser execution in LDAS
The following diagram explains the different steps that take place within LDAS as it picks data/file generated by the instruments and transforms it into processed data for downstream usage using the parser.
For a developer attempting to build the parser that enables the steps mentioned above, it is imperative that the parser is developed in accordance with the expectations set within this guideline.
Building a parser for LDAS
The different components that help to build a standard, acceptable parser for LDAS to function as expected are covered in this section.
Convention and folder structure
- Create a main.py file and it should contain the main() method as an entry point to run the parser.
- Refer List of Parser’s input parameters table and provide the input parameters to the main() method.
- Add other required source/script files and dependencies in the parser package.
- To package the parser, execute the automation script (parser_execution.py- which will be delivered along with other services) with necessary parameters mentioned below.
- “script_path”, which refers to the directory where the Python scripts are located and “parser_name”, which is the name of the parser.
- Execute the below command to package the parser as zip file extension.
python parser_execution.py <script_path> <parser_name>

Command to run the parser
- The zip file will be created in the same directory as the parser_execution.py file is present.

Generated parser zip file placed in the directory where parser_execution.py is executed
- Refer below diagram to make sure the zip file is in the expected structure to run in LDAS.
- <ParserName>_<VersionNumber>.zip
- <ParserName>_<VersionNumber>
- <ParserName>
- Pythonscript.py
- <ParserName>_<VersionNumber>
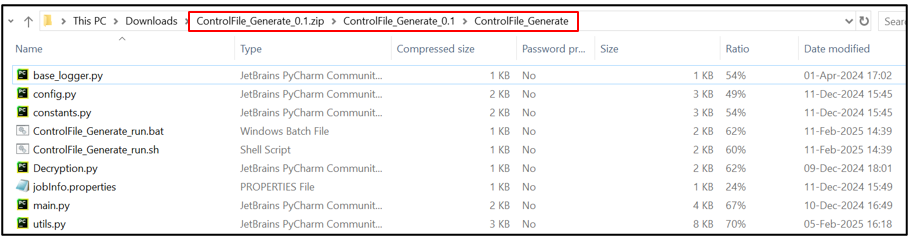
Parser package structure
NOTE:
- LDAS will not execute the parser, if it does not adhere to the specified format and folder structure.
- After zipping, ensure that the ‘.bat’ and ‘.sh’ files are present in the final folder structure, i.e., inside the <ParserName> directory.
Naming Convention
The expected name for the parser package is "<ParserName><VersionNumber>" where parser name and version number should be separated by “”. No other special characters are allowed in the naming.
For example, if the name of the parser is “ControlFile_Generate”, then the parser package should be named as “ControlFile_Generate_0.1”, where “0.1” is the version separated by “_”.
Input Parameters
The following parameters are passed as input from LDAS to parser’s main method.
Parameter Name | Description | Purpose |
|---|---|---|
file_name | Unique Activity ID | Unique Reference ID for activity tracking. |
temp_path | Path of the working directory in which LDAS will place the instrument files. | Whenever any instrument file is received, LDAS will place the file in a dedicated working directory. The parser will use the same location to generate output files. |
fileSeparator | Delimiter used as the file path separator. | This character must be used by the parser for file path separator. Use “\” for windows and “/” for linux operating systems. |
tika_url | Tika service url | Endpoints to read the content from pdf files. |
grpc_details | Host-port connection details | Used to establish a connection with LDAS to fetch the required data. e.g. gRPC is used to retrieve metadata from the LDAS Metadata Management page. |
parser_name | Name of the parser | <ParserName>_<VersionNumber> |
log_path | Path of log files | Path where the parser logs are written. |
List of Parser’s input parameters
LDAS Woking directory structure
The LDAS working directory will include the folders: ‘input’, ‘output’, and ‘metadata’. If you select the "Push to Workflow" or "Pull from Instrument" options while configuring the instrument in LDAS, you must also create two additional folders in the working directory (i.e., temp_path):
- workflow – for placing the ‘workflow.result’ file
- internal files – for storing ‘<instrument file name>.response’ files
The working directory structure will be as shown below:
- Working directory
- input
- output
- json
- Output files in zipped format
- json
- metadata
- input.metadata
- output.metadata
- workflow
- Workflow.result
- internal files
- <filename>.response
Input Directory
LDAS will create a folder named “input” inside the working directory (temp_path) and place the instrument sample files there for parsing.
The parser should retrieve the “temp_path" parameter from LDAS and use it to find the instrument files.
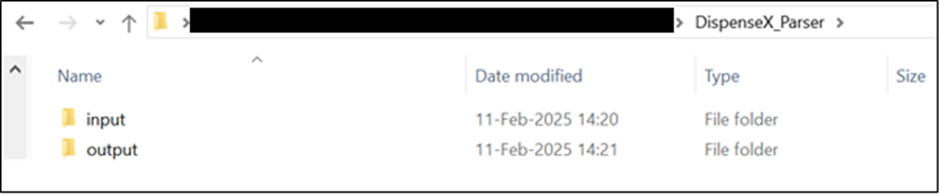
Input folder structure
Output Directory
LDAS creates a folder named “output/json” inside the working directory (temp_path). The parser needs to store the output files in zipped format as shown below.
- Working directory
- output
- json
- Output files in zipped format
- json
- output
LDAS will process the output files, only if it finds a “.zip” extension inside the json folder.

Output Zip file location
The output files should be present immediately after extracting the zip folder

Contents of output zip file
Result File (Push to External System)
Processed json data from instruments can be pushed by LDAS to multiple connected external systems. The expected parameters for the external system should be stored in separate file with “.result" file extension and be in the same directory as the desired output file.
It is recommended to use the external system name as the filename for the “.result” file. For example, if the external system is ‘Sample Manager’, generate a result file with the filename “SampleManager.result”. LDAS will process the ".result" file that matches the name configured on the instrument page. If data needs to be pushed to multiple external systems, the parser should create multiple “.result” files, and the external systems should be configured within LDAS.
To push data to the target external system, the “.result” file's content should include the key "ResultData". The content of the "ResultData" key may vary depending on the external system.

result file format
Metadata
When you opt for LDAS's archival feature, the archived files can be tagged with metadata. The necessary metadata information should be present in the “.metadata” file. This section outlines the standard structure and file placement required for proper metadata tagging.
Metadata Structure
- File Format: The metadata for each file should adhere to LDAS's standard metadata structure to ensure accessibility.
- File Extension: Metadata files must have the “.metadata” extension.
- For input files and folders, the metadata file should be named as “input.metadata”.
- For output files and folders, the metadata file should be named as “output.metadata”.
NOTE:It is necessary that the metadata keys present in the metadata file, should be created in the “Metadata Management” page of LDAS.
The valid date formats for metadata values in a metadata file are as follows:
- Valid date range format: "dd/MM/yyyy - dd/MM/yyyy"
- Valid date format: "yyyy-MM-dd"
- Valid date time format: "yyyy-MM-ddTHH:mm:ssZ"
Metadata File Location
The metadata files should be in a directory named “metadata” within the working directory (temp_path). This ensures LDAS can access them during archival.
- Working directory (temp path)
- metadata
- input.metadata
- output.metadata
- metadata

Input and output Metadata file location
Metadata File Contents
Metadata should be stored in JSON format, where each key represents either a specific filename (with extension) or a folder name, ensuring accurate tagging of metadata to the corresponding file or folder.
For subfolders and nested files, the key must include the full relative path, and the value should contain the metadata to be associated with that item.
This same structure should be followed when tagging metadata for e-signed PDF files. The metadata file should have its contents in the below format:

Metadata for single file

Metadata for multiple file or E-signed PDF
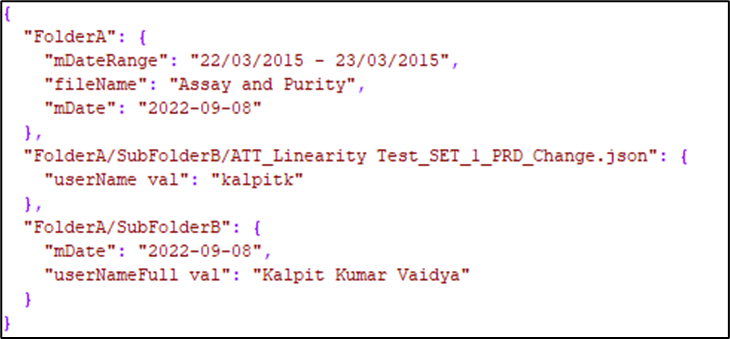
Metadata for nested folders
NOTE:Except for the filename and e-sign.pdf, all other metadata keys present in the ‘.metadata’ file must be configured on the LDAS platform Metadata Management page.
Tag Metadata
When the 'Tag Metadata' option is selected during instrument creation in LDAS, users can associate user defined metadata with instrument data files or parsed output files, enabling enhanced search capabilities based on the tagged metadata.
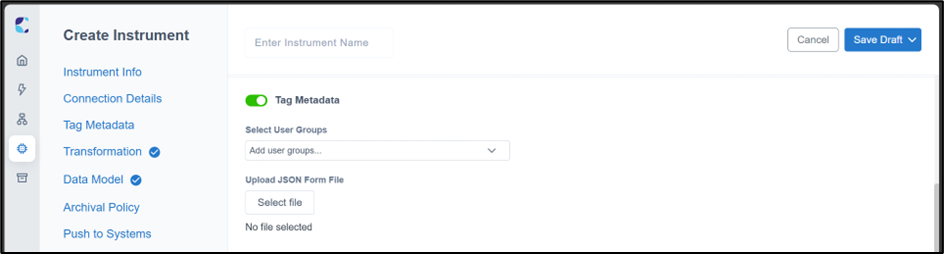
LDAS - Instrument Creation-Tag metadata option
A JSON form defined during the 'Tag Metadata' stage specifies the metadata keys to be used for tagging. This form is presented on the ‘Activities’ page when an activity is generated, enabling users to input custom metadata. Upon submission, two files “input.metadata” and “output.metadata” are created in the metadata folder within the temporary path.
If the metadata folder already contains existing metadata files before parsing begins, the parser must include logic to update those files with any new metadata extracted during the parsing process. This ensures that previously stored metadata is preserved and enriched, rather than overwritten or ignored.
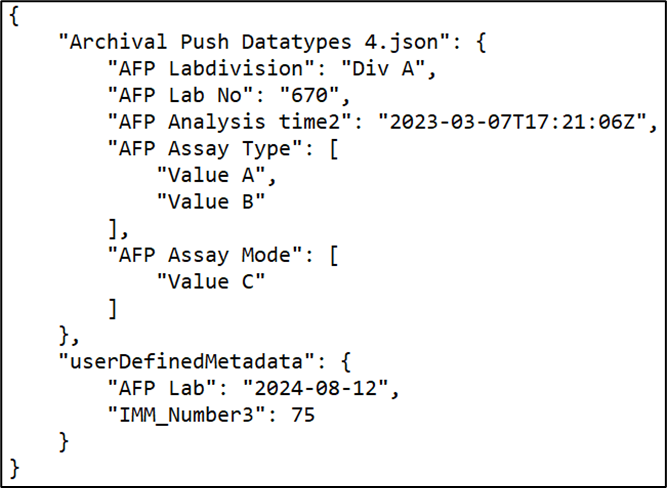
Metadata file content with user defined metadata
Push to Workflow
You can integrate with the Orchestration module of LDAS, where actions such as launching workflows or completing specific tasks of launched workflows can be performed through Instrument's activities. Additionally, instrument data can be pushed as attachments, either as files or links, if the files are archived internally, and experiment or sample details can also be set as workflow parameters. These actions can be done based on the configuration specified in the parser.
Workflow File Location
The Workflow.result file should be in a directory named “workflow” within the working directory (temp_path). This ensures LDAS can access them during “Push to workflow”.
- Working directory (temp path)
- workflow
- Workflow.result
- workflow
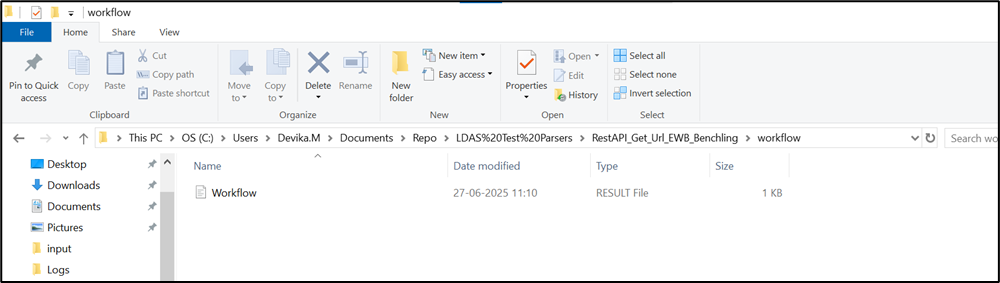
Workflow.result file location
Workflow File Content
The ‘workflow.result’ file content is expected to be stored in a JSON format as shown in the below figure.

Workflow.result file content
Key Name | Definition |
|---|---|
modelName | The name for the BPMN model that will be published in LDAS. |
workflowAction | Indicates the action for the workflow. It can be either “LAUNCH” to launch a new workflow or “UPDATE” to update an existing workflow. |
workflowId | The ID of the workflow (workflowName) that needs to be updated. This should be empty for new workflows. |
files | An array of files to be attached to the workflow. Each file object contains the name of the variable to which the file will be attached or the name of the variable where the link will be stored. |
jsonContentToVariableFiles | A list of files whose entire metadata content from the file will be incorporated as process variables within the workflow. This can be left empty based on the needs. |
attachmentType | Specifies the type of attachment. It can be either: • link: Stores the archival link of the file as a variable (usable only when internal archive is enabled). For ‘attachmentType’ of link, user should either provide “INPUT” (Input archival link will be shown) or “OUTPUT” (Output archival link will be shown) • file: Adds the file as an attachment in the workflow. |
processVariables | While launching the workflow, if there are any variables needed to be defined for the workflow, it can be provided here as a JSON object. |
organizationHierarchyPath | The path where the model must be published |
messageName | The name of the message. |
correlationKey | The correlation key of the message given for the task |
Internal Files
Whenever the instrument “Initiation Method” is set as “Pull from Instrument” in the Instrument configuration of LDAS and “Return Response” is set as “Yes”, it is imperative that there is a file present with extension “.response” in the “Internal Files” folder.
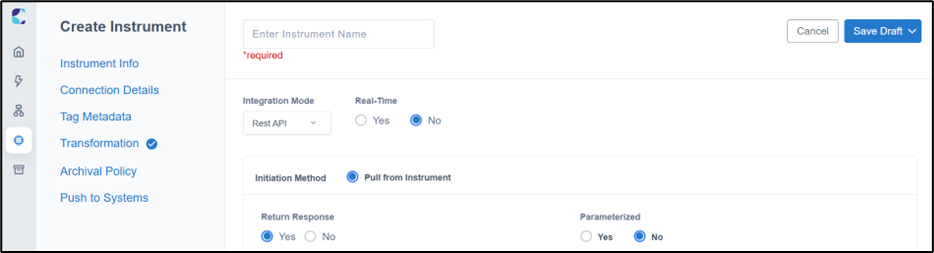
LDAS Instrument creation page for Pull from Instrument
Response File
The system expects the “.response” file to be located inside a folder named “internal files”, which must reside within the working directory (temp_path). The system will only send a response if a valid “.response” file is present in this specific location. The file can have any name, as long as it uses the “.response” extension.
Below is the required folder structure for placing the response file.
- Working directory (temp path)
- internal files
- <filename>.response
- internal files

Response file content
File Attribute Directory
In the working directory (temp_path), there will be a folder named "file attributes". Inside this folder, the file attributes metadata will be present as “file attributes.metadata”. The file attributes contain default metadata parameters like
- Instrument name
- Instrument Type
- Owner
- Initiated By
- Raw Data Last Modified Date
- Organization path.
By reading this file, the parser can retrieve the necessary instrument details and process the data accordingly. Structure of “file attributes” shown below
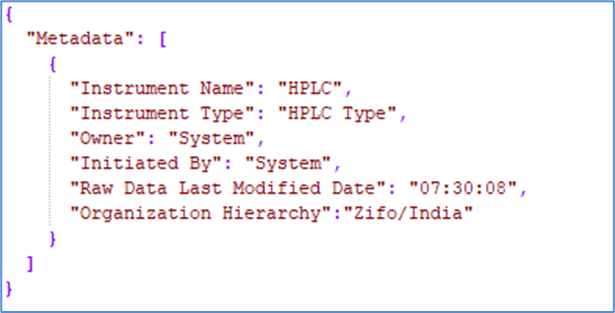
File attributes structure.
Parser Logging Standards
Exception Logging
- When an exception occurs, log the message using the format:
Parser Exception: "<Error Message>" - Use the following implementation in parser while handling Exceptions:

Sample python code for logging the Exception.
- The parser must exit with a value of 1 (eg. sys.exit(1)) as mentioned in the above figure, when an exception is encountered. This exit code informs LDAS that the parser has failed. If not set, LDAS assumes the parsing stage was successful, which may result in irrelevant or misleading exceptions during subsequent processing.
- Parser logs must follow the standardized logging format defined below:
LOGGING_FORMAT = "[%(asctime)s] %(levelname)s [%(filename)s:%(lineno)d] %(message)s"
- asctime – Timestamp of the log entry, including milliseconds.
- levelname – Logging level (e.g., INFO, ERROR).
- filename – Name of the script generating the log.
- lineno – Line number in the script where the log was generated.
- message – The actual log message or exception details.

Sample log file data
NOTE:When the above steps are followed, LDAS will automatically render the parser exception message on the activity page. Refer below figures for a detailed view of the log file data containing entries from all previous executions and for activity page displaying the most recent parser exception message
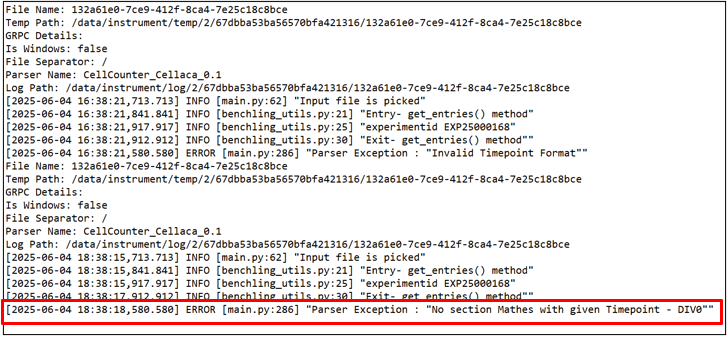
Log file data containing historical log entries
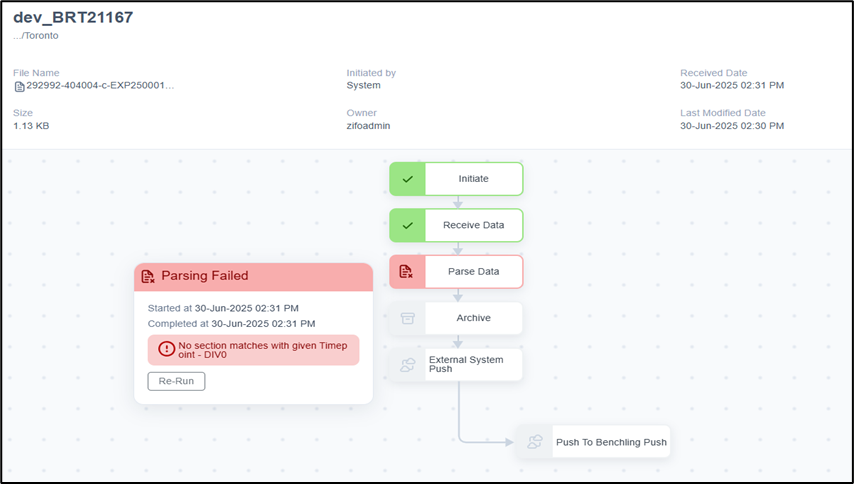
LDAS Activity page showing the recent occurred parser error
Generate Logs to Designated Path
-
Retrieve the log_path and file_name from the parser’s input parameters.
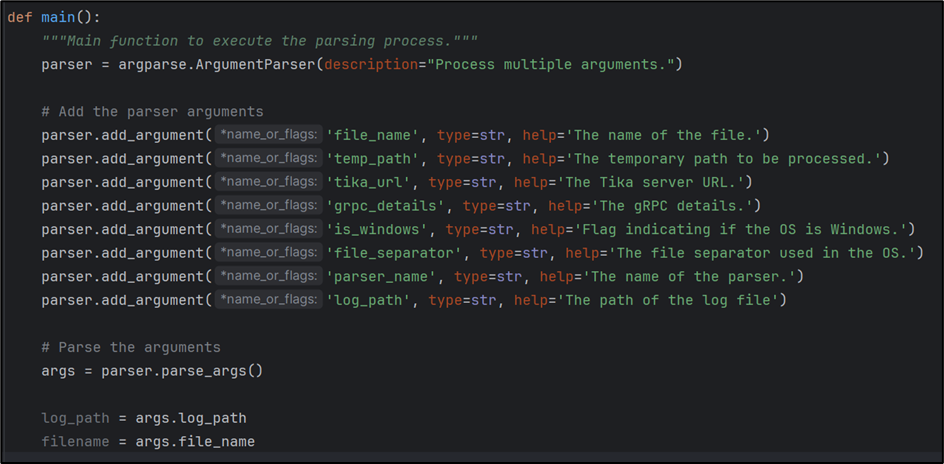
Retrieving log_path and filename from input parameters
-
In the base_logger.py file, use the “log_path” and “filename” input parameters to construct the complete log file path in the format <filename>_parser.log, as illustrated in below figure
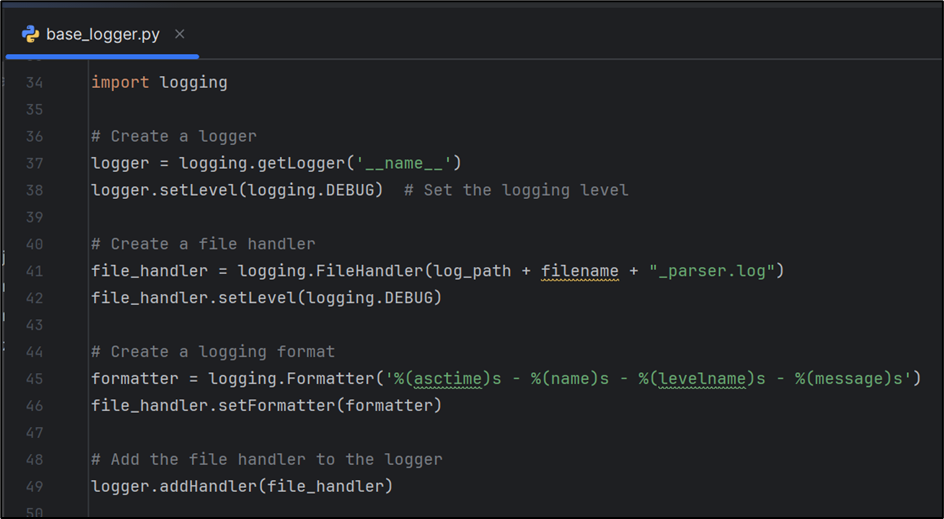
Constructing log file path in base_logger.py
Parser log file name
- If log file is present, append the new log entries otherwise, create a new log file in the given log_path.
NOTE:To enable downloading of the parser log along with the activity log, the following standards must be followed as outlined in Generate Logs to Designated Path section